
Space Efficiency with VMAX All Flash
I partnered up with Scott Delandy (@scottdelandy) for another fun demo around space efficiency with the VMAX All Flash. In this one we use candy to explain compression, snapshots and thin provisioning. Enjoy!
Demystifying Deduplication
With the emergence of flash technology, the need for deduplication rose due to the expense of the drives. Deduplication has become a blanket term to span a range of space-saving technology from snapshots to zero-space reclaim. Here, I am going to try to break it down in the way I do to my customers.
As usual, the TL;DR:
1. You say you offer deduplication. I do not think it means what you think it means. – Always ask for specifics.
2. As it turns out, you’ve got deduplication on that 10 year old array hidden in your garage! Congrats!
3. Wait? How important is this to me? The answer, as always: it depends.
Deduplication. You keep using that word.

When people ask if we offer deduplication, many vendors will say yes. In the minds of our customers, deduplication in its purest form is single-instance data storage. In order to do this successfully, the sweet spot is around 4k or 8k IO. Most workloads are bigger than that, which leads to the need to break the incoming write into smaller chunks to enable that level of data reduction. This means that CPU and memory resources have to be dedicated to this task and care must be taken to architect the technology to account for this additional workload. The benefits can be massive because it means that every small block of data that matches that 4 or 8k block can be written only once and accessed by all at the array level saving both drive writes as well as an incredible amount of space. Even then, the implementation of single-instance data storage varies: some will only do it when the array is under light load, others do it all the time. What good is deduplication if it is only performed when the array is not busy? What happens when you drive heavy workload consistently? It is important to ask for specifics in this space and learn what you are getting and how it may apply to your workload. So what does deduplication really mean and why such a slippery slope? Wikipedia, FTW: “In computing, data deduplication is a specialized data compression technique for eliminating duplicate copies of repeating data. Related and somewhat synonymous terms are intelligent (data) compression and single-instance (data) storage.”
As it turns out, you’ve got deduplication on that 10 year old array hidden in your garage! Congrats!

By the definition above, data deduplication can also include snapshots. Snaps have been around for over 10 years now. If you have an old decommissioned array in your garage, odds are you have “deduplication” on it in the form of snapshots. What makes snapshots so awesome now is the ability to use them at little to no performance penalty –mileage varies by vendor and platform, be sure to ask the question. Snapshots enable lun-level “deduplication” where the same lun or set of luns is copied and presented for backup, reporting or other needs as a performant alternative that enables the production host to focus all resources on production workload while the array seamlessly presents a safe, tracked copy of that volume to other hosts for necessary processing. By definition, this is a form of data deduplication, but it doesn’t quite scale to the same benefits as single-instance data storage. In fairness, with my customers I tend to classify snapshots as part of space efficiency along with compression, but some do not make that distinction.
And now for the dreaded “It Depends”
I could start a bit of a battle over technical religion and tell you what I think about deduplication and snapshots and what is really important, but the truth is that it all depends on your workloads and business needs. In the case of VDI, VSI and some other workloads even as the price of flash decreases, deduplication is absolutely worth the additional processor and memory resources thrown at it. Running a large block workload or a data warehouse? Snapshotting is probably good enough because that CPU and memory is probably better used servicing reads and writes. Many things fall in that in-between category and can go either way. What’s most important to your business needs? You can talk to your application owners and for once say “as you wish” or at the very least…

Stop the Insanity: A Practitioners Guide to Copy Data Management
I’ve been doing replication automation and application integration for a decade at EMC. I got into it early on because few people wanted to touch it and I was the new kid. Why?

I’ve kept it all these years because of the extreme value of this conversation with our customers. Many of my customers have application teams that need to enable quick reporting on their applications outside without taxing their production workload. The frequency of this need ranges anywhere every hour to weekly. The good news is that it is now easier than ever to give your application owners the ability to schedule and create on-demand, application-consistent replicas to meet your business needs with Appsync. Let’s take a look at how to do this right.
The TL;DR:
1. Standardize your builds. Integration problems happen with pet configurations.
2. Bring your DBAs and App owners in early. They know what they need and where their bodies are buried.
3. The devil is always in the details. Don’t assume that because a tool has App integration that it supports every configuration of that app.
Standardize your builds

While individuals on your team may be unique, your server/app builds should not. Implementation challenges come with introduction of any technology; the most challenges come with unique configurations and one-offs. If you adopt consistency across your builds and standardize, the problems you encounter will be minimal in comparison. Appsync will plug into your host environment and discover the devices related to your app, create matching storage for you and create an application consistent copy for Oracle, SQL, VMWare or Exchange. This eliminates a lot of the work in trying to match your backup and reporting environments to your source. Change your production app to include more storage? No problem! Appsync will discover that and make the adjustments in your target storage and reporting/backup environments too! So easy, no one has to lift a finger. You can chill like this awesome guy:

Bring your DBAs and App owners in early
Ever play telephone? It can be really fun to see what comes out the other end -unless you are counting on that kind of communication to run your business.

Bring your app owners and DBAs into the conversation. They know the special configurations and requirements of the app/DB environment that are going to impact your success. Odds are, right now they are going rogue and creating their own database copies the hard way. Why not be the hero and give them a seemless, automated technology that cuts their time to value by up to 5x? If you are running all flash, you can become a real storage hero by introducing 5-20x space efficiency while maintaining that high level of performance that meets the needs of the DBAs. Requirements such as RPO can be plugged into Appsync for reporting on SLAs. Appsync even gives you a cool dashboard to report on those SLAs. The configuration details can also be preserved and manipulated to fit your backup and reporting needs. You can give your DBAs access to their specific application environments within Appsync to allow them to set these advanced configuration parameters automatically without interfering with the other Applications in Appsync control. This keeps the storage admin from playing telephone with the application teams and allows the application teams to create the replicas they need with little more than a little policy setting on the part of your storage admin. These policies can limit application access, the number of copies created and limit the ability to restore to production for the ultimate in protection.
The devil is in the details.
One of the common mistakes that integrators make is making the assumption that support for a specific application or widget implies support for all configurations. This is not always the case.
Some application configurations cannot be supported and automated by tools for a variety of reasons. The inclusion of your DBA team as well as a good read of the release notes for any product that enables integration is advised before you deploy your solution. Don’t have a supported application? For tricky applications such as EPIC, you can create crash-consistent, file system replicas on the fly. It doesn’t have all of the cool bonus hooks, but it’s much better than scripting it all out and trying to support it. On the other side of the coin, many tools will only support specific storage platforms. Appsync covers the breadth of the Primary Storage portfolio at EMC: Recoverpoint, Unity, Vipr Controller, VMAX, VNX, VPLEX, and XtremIO.
With all of the options and features available in Appsync, why not choose this easy button for your backup and reporting environment? It intergrates tightly with the application and storage environments to allow you to standardize on a single solution for automating your replication needs. It offers the ability to give your app owners and DBAs control of their own environment without overrunning others leading to fewer integration issues and urgent storage team requests. Appsync will also work to automate your crash-consistent copies for unsupported applications. Copy Data Management doesn’t have to be hard anymore. Deploy the easy button for application-integrated reporting and back up and give your business time to focus on what’s truly important: the best experience for your customers.

Email is Dead! Long Live Email!
Saturday I woke up to a message from Twitter that said “You have reached 700 followers”, shortly followed by a message that updated the number of followers to 800. Given that I had been at barely 600 followers on Friday and it was early on the west coast, my initial thought was: “Go home Twitter, you’re drunk.” I started my morning routine, went for a run and later hopped on Twitter to confirm my follower count at 600… only to find it hovering around 800. What? I had been relatively quiet on Twitter, and as cool as the posts that I knew of referencing me have been, they aren’t the type to generate 200+ new followers on a Saturday. Naturally, my reaction started with concern: “I wonder what I’ll get to apologize for today! The possibilities are endless!”

(It really is too easy – I’ve spent too much time apologizing this year.) Then I thought “wake up your kids, I have a lesson in social media to share! It turns out all of that stuff I say to the school kids about the permanence and reach of your internet posts are true!” A simple Bing/Google search revealed the most likely source: this fun little Phrasee article. Cool Story. Oh and look there’s another one about the same Tweet! It’s like Christmas! why did I tell one of my best friends that email is dead for all to see on Twitter? Have I failed at Social Media? Isn’t the primary purpose for things like Twitter interacting with like-minded people about what we find important?
As usual, the TL;DR:
1. Email is not an effective two-way communication method for me and many of my peers in the industry.
2. Social media and mobile communications are a more effective form of communication if you want a rapid response from my demographic.
I put that tweet out there to exaggerate my opinion as many do in a forum that is limited to 140 characters or less, to socialize to my followers an effective way of communicating with me and to start a conversation about the way mobile is changing our lives. In a world where many of us are constantly staring at their mobile devices, I am inundated with information that varies in value. The value for me in email at work is as a means to search for internal information on the products I support, to send documented requests for assistance and to blast the occasional “in case you missed these 3-5 important things happening” email to my people. To me, email is an ineffective way of two-way communication because I receive a massive amount of email both professionally and personally every day. On the personal front, I can count on my email service to filter out spam and promotions with relative success. Professionally, what I get isn’t spam, but it doesn’t usually require an immediate action or attention either. It’s there as an FYI or item of note – and whatever it is will probably change at least a few more times before I really need to know it. I could try to read every email and commit all of this information that is constantly changing to memory, but if I did I wouldn’t be very good at doing my real job: talking to our customers, engaging/leading our people and of course making the number. I am still sitting on around 20,000 unread emails. I search for the important stuff in my free time. I read emails from key people in the company: my people, leaders and the occasional troublemaker. I check subjects to get a feel for what my day will be like much like people used to check newspaper headlines. While I do not think email is going anywhere anytime soon, I definitely think its use as an effective way of communicating in more than one direction has reached its “best before” date.
Social Media and mobile communications are a more effective form of interactive communication for me and many people like me. I travel a lot for work. I spend a significant amount of my time on planes or in transit. As good as technology has gotten, plane WiFi for things other than IM communications is a crap shoot at best. I get so many PowerPoints sent to my email that half of the time I don’t get the good email updates until I land.

IM, iMessage, Twitter, all of that goodness almost always works if Wifi is up. I can be an effective worker and communicator with those applications, email is too cumbersome. I can market who I am and what I am passionate about to anyone who cares to look and they can make the choice to engage me in conversation or not. The last time I took advantage of an email deal was about 5 months ago. I may open one ad a week. I’ve bought at least 5 things via targeted marketing on various social media platforms since then. What’s the difference? In my experience, the emails tend to be a wide blast with a catchy title that I always feel guilty for clicking Targeted advertising via social media already takes my interests, age and lifestyle into account and comes up with pictures of items that I may want to buy. Example: On Facebook my best female friend gets an add from a clothing company for a Doctor Who shirt. I get this:

It’s ok to laugh, I did. I value exercise over time in front of the TV and I find humor in these things. I am the type to wish someone a day based on their opinion of something I like… “If you don’t have something somewhat nice to say, well it’s your choice to have that kind of day.” I don’t have a PHD in marketing, but that is good marketing. That is how you reach a generation of young talent who is too busy focusing their time on making a difference: targeted ads with imagery that fits right into their lifestyle. I am cautious of anyone who touts any one answer as the best form of communication. I am an engineer and a leader. Show me statistics that say that email is the best form of marketing, I will show you a clever statistician that gets paid by an email marketing firm. The answer always lies between ones motives and “it depends”. As with most cases, the tools you need to do the job depend on the outcome you want to achieve. Social Media is a more effective way to engage with me and many of my peers. I prefer to engage my customers directly in person when I can because they appear to retain more information and have a better experience than they would through email or webcast. It shows them I care enough about their business to speak directly. There are other demographics that do better with TV, email and other forms of marketing. Who are you trying to target? Why should they care? What is your end goal? All of these questions and more lead you to the right tool to do the job.
Thanks to phrasee for the free press and the opportunity to have a more meaningful discussion! Open season readers! What works for you?
EMC World Adventures – The Chicken Wing Demo
I recently had the honor of joining Scott Delandy and the EMCTV team in the Geek Pit at EMC World to explain the architecture, pricing and packaging of the VMAX All Flash… with chicken wings and beer. It was a lot of fun! Here’s the video:
The concept for the video came from the need to explain the new product simply. Parts of this demonstration could also be used to explain our Unity storage platform as well: appliance-based pricing and packaging, no-compromise snapshots… it’s great! (More on this in a separate blog!)
Behind the scenes the effort to put this all together was interesting. There’s a ton of coordination, planning and talent behind the scenes on a production like this. The EMCTV team put in a lot of effort and consideration into how we could take this demo from good to great on a little info. Being joined by JB and Lara added even more fun to the dynamic. The EMCTV team is stacked with great talent and it was great to join them for this adventure.
So what did I do to prep for the demo? I ran through the basic components of the demo on my own 4 or 5 times that week to make sure I had the main points covered. Scott and I did a run through in the social media lounge at one point earlier in the week. I picked up the liquid props the night before and smuggled them onto the set. I had a session to support and customer meetings all day that required a more serious wardrobe than what I wore for the demo. The meetings were about leveraging the power of the portfolio to enable specific customers to achieve business results. I wrapped those up and hopped a cab to pick up the wings. Getting back proved to be a challenge due to an accident on the strip. I got back, hit the room to change and sprinted down to the set for hair and makeup. Once that was all set, it was a matter of getting the props ready and adjusting the demo in my head to include more than one other person. All of the hard work was done by the EMCTV team, and they really made this demo look and sound awesome!
A special thanks to Matt Dunfee @dunfee16 for letting us invade the Geek Pit for this demo and an SRDF Metro Demo earlier in the week. (Posting soon!) it was a great time sharing our technology with our customers and partners in such a fun atmosphere!
The Magic of Space Saving Technology
Scott Delandy and I teamed up for another fun video to share a simple explanation of technology -this time with a magic trick! In this video, we cover space saving technology typically used in storage arrays: thin provisioning, snapshots, deduplication and compression. More technical details on all of these things below, but please check out the video:
What I love about this video is that it is simple, storage agnostic and fun. Anyone with a basic understanding of computers should be able to understand the concepts at a high level. So let’s discuss the importance of each, how they are used in the industry and how they apply to EMC technology.
Thin Provisioning
Thin provisioning is used just about everywhere today. Simply put, thin provisioning shows a disk to the host at whatever size you choose, say 1 TB, but only writes the data the host writes. It’s pretty common in the industry to see people claim that thin provisioning will gain you 2:1 in storage efficiency. Why? Because hosts rarely use all of the capacity we give them. We can take the data the host writes and distribute it across a large pool of disks thanks to the use of virtual provisioning. The devices given to the host share the resources of a larger pool of disks instead of being localized. The data location for each device is tracked separately with pointers called metadata. In the early days, we could get in a bit of trouble in the database space when the DBAs would write 0’s to newly created database volumes. This was solved by “zero space reclaim” initially where the array could go in post process and manually clean up the zeros written out. Now, we just don’t write the zeros. We would also eventually have issues because of the way Operating Systems handle deletion of data: marking it for deletion instead of writing 0’s. This is now handled by intelligence based on the OS that will clear this “deleted” data for us. The most exciting advance in thin provisioning for me is the introduction of all-flash array technology which means no compromises in performance to use thin devices over devices that are fully written out.
Snapshots
Replication technology has been at the heart of our Customer’s business needs longer than the 10 years I have been in the storage industry. Since the introduction of snapshots, which are point-in-time pointer-based copies of of a given source volume, customers have wanted to implement them exclusively because of the space savings they provide. The problem with traditional means of storing data is that those volumes all point back to the spinning disk, which is a significant performance degradation on both production and the copies. With all flash systems, we can now provide the performance of a full copy, without sacrificing the performance of production and the subsequent copies. We can make more copies with equal performance and save a ton of space! What happens when new data is written to the source or a snapshot? That just gets redirected to new space. Simple. The space savings you get with snaps isn’t X:1 because of the changes written to the source and snapshot volumes, but depending on the workload, it can be very significant.
Deduplication
Deduplication works by inspecting small chunks of data to see if they match, then only writing that data once. This means that multiple hosts that share the same storage system can share the same chunk of data using pointers similar to that of snapshots. Deduplication can work really well with some workloads, specifically VDI/VSI where we have seen ratios in the 12:1-15:1 range. XtremIO is our flagship product in this space. XtremIO is awesome because deduplication is done in-line all the time with consistent low latency. In-line deduplication is an important differentiator because sorting through the data and consolidating after the fact is inefficient, takes up extra space when you need it most (when the array is busy) and adds unnecessary utilization to the system and drives. For database workloads, deduplication doesn’t work as well. For those workloads, better reduction can be achieved by using compression.
Compression
Compression reduces the data by applying an algorithm that allows for reduction of 1’s and 0’s written to disk without losing any data. It’s more complex than that under the covers, there’s some serious work that goes into making compression work on a given technology. Again, mileage varies here based on your workload and data. Some things compress well, others not so much -specifically if the data is compressed at the host level. All of our all flash array technologies will offer compression. XtremIO has it available and completely in-line today. In line compression will be available on the VMAX All Flash later this year. The reasons for in line compression over post process (or in line that becomes post process when the array is busy) are the same as those outlined above for deduplication. A rule of thumb reduction estimate here is 1.8:1-2:1, but it depends on the data you are storing. In most hybrid array models, compression comes at a significant performance penalty, but with the enabling technology of all-flash you don’t have to sacrifice nearly as much performance for space savings.
While we employed a fun magic trick to illustrate the concept of no compromise space-saving technology, at the end of the day there’s no magic to this stuff. It’s all just some well-written software that makes really cool technology even better. I hope you enjoy the demo. As always, I welcome your thoughts.
My Intro to Management – a Bucket, a Mop and an Illustrated Book About Birds
This was supposed to be my first post back from my hiatus, but I had two on scale that came first. Here is the post as it was written. It seems fitting to post this today. It’s been a while since I’ve posted anything. I’ve been writing a lot, but the tone of many of the posts just wasn’t where I wanted it. My professional life has changed quite dramatically from the last post. I am now a member of the Leadership team! I help drive the Primary Storage number for the Americas. I’ve learned a lot over the past few months. I’m going to try to stick to the top three.
The TL:DR:
1. Always take the help with the bucket (and help others with theirs too!)
2. The mess you expect is rarely the one you get. Keep your mop handy.
3. The vision you paint needs quite a bit of maintenance. What started as a drawing of a single could very well evolve into an illustrated book about birds.
Always take the help with the bucket (and help others too!)
I spent quite a bit of time in November writing up a business plan and talking to the bulk of my stakeholders about it. I took their input, made a few modifications and had a rock solid plan entering January by the time I found out that I had the job. A week later, massive amounts of change came rolling in. The plan was solid enough to roll through the changes, but it was clear that it needed some adjustments to account for the new teams that needed our help, new products and other roll outs. I had a bucket full of things to do and more and more things kept flying in and forcing other items out of the bucket.

I started talking to people about my plans. Those who were in offered to help. Scott Delandy jumped down the rabbit hole with me on this idea and put in a lot of effort to make it successful. He and I made a video explaining the appliance modeling for the VMAX All Flash with beer! (See previous post.) Lauren Malhoit got me out there on the In Tech We Trust podcast to talk about my role, changes taking place in the industry and other things. The next step there will be an interesting one! I’ve been on the road every week since taking the job except for one, When on that kind of travel sprint, it’s really hard to get all of the extra administrative stuff done, coordinate schedules and keep up with everything that is going on. By hard, I mean impossible to do alone. I’m fortunate to have a team that can divide and conquer, but also to have people in the field that have enough faith in me already to call when they see something that needs attention. I recently caught a dinner with a few other EMC Leaders in Boston. I sat with a few of them and two pulled me aside to give me some encouragement. That whole conversation brightened my spirits for days afterwards. Sometimes all it takes is finding a way to show that someone notices what they are doing and that it matters to make their outlook much brighter. That started a chain of me going out and finding people who were in the same boat: helping, under time pressure and working as hard as they can. Then all it really takes is showing them that I notice. It’s made a huge difference in morale and outlook for the team. I highly recommend taking a step back from a stressful situation and finding those key people that have been putting in the extra work and showing them some appreciation. So many people grind these things out in an atmosphere that feels thankless; a change in tone or a thank you can take you a long way. I am working to get my team to do the same.
The mess you expect is rarely the one you get. Keep your mop handy.
A week into the job the biggest problem I thought I would have in moving the needle and driving results with my team was solved for me. I picked up a new problem: How to help an entirely new set of people, most of which were new to the platforms we support. This is not a bad problem to have to solve at all. More help is always welcome! That said, any time such a shift in priorities happens, a lot of questions come out of the change. Most of my time has been spent talking to people about the importance of this change and how it will be better for us and for our customers. One off my favorite mentors once pulled out a hierarchy of human needs and shared it with me.
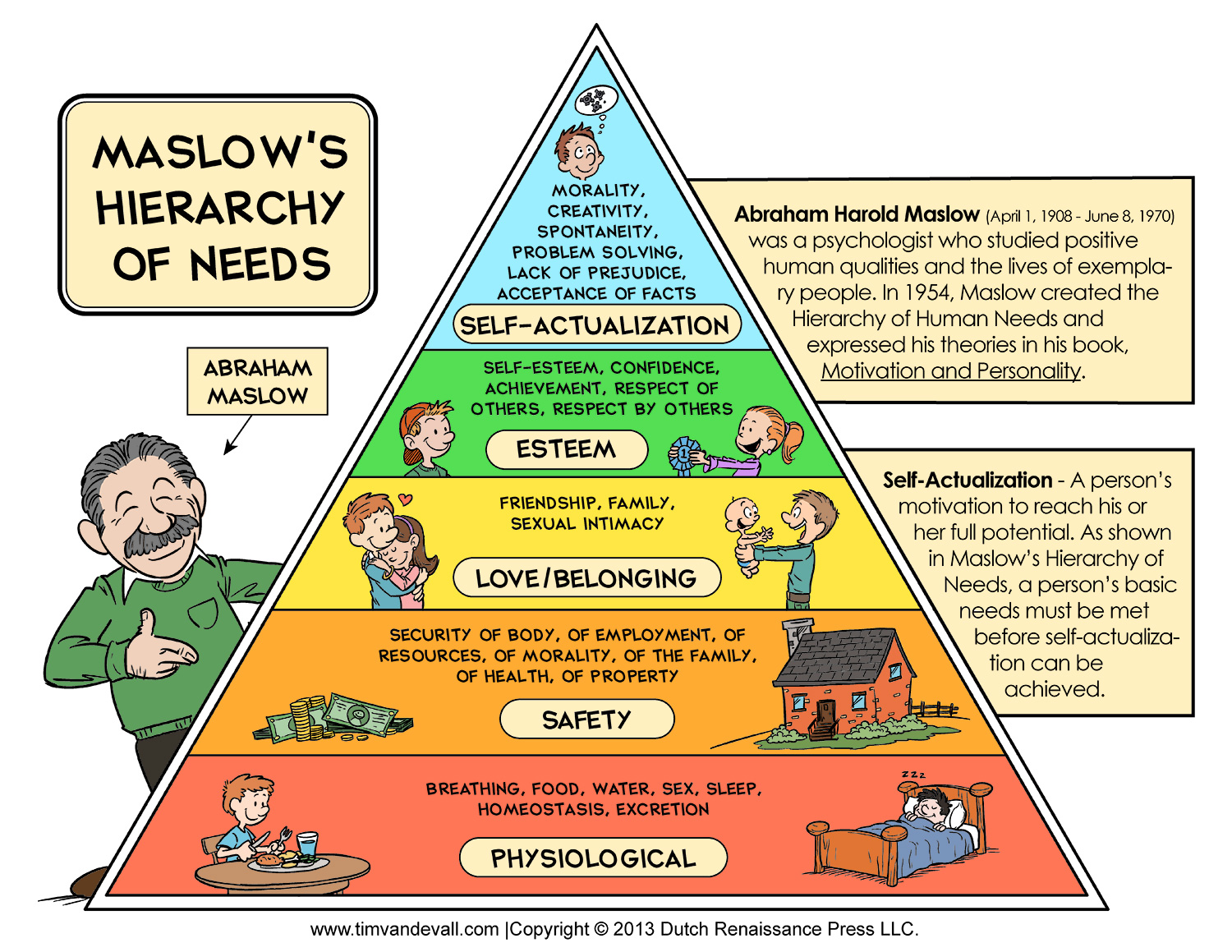
A lot can be learned about how to help someone based on what stage they are at in the hierarchy. This is where the mop comes in. A lot of my work these last two months has been in apologies, genuine assurances and thank yous. It’s about learning how people want to be treated and interacted with: where they find value in their role, what they want to do next and how they prefer to interface with others. This is one of the most messy but also the most rewarding parts of what I do. I come in every day trying to puzzle out how to bring the individuals and the teams closer together… connecting people, discovering what works and what doesn’t.
The vision you paint needs quite a bit of maintenance. What started as a drawing of a bird could very well evolve into an illustrated book about birds
Maybe a Bob Ross reference would have been better, there is always room for more happy trees, but that would have totally killed the Meat Puppets/Nirvana reference. Ideas evolve and change. The simplest concept can grow into a big production, or die on the vine. With the amount of work to do, the best way to do it is to talk to people. Find those people with similar interests and make a suggestion. Once that happens, see where it leads -everyone will have their own spin. The ideas will change and that’s ok. I would love to be the person who just goes out and executes on these things, I had fun doing that stuff. The problem is scale. I can’t drive what’s needed if I do it all. That means some ideas will fail, but it also means that others will succeed in ways I haven’t considered. For the failures, there’s always a chance to try again. I’ve spent a fair bit of time in the past month worrying about getting it all done. More and more, I’m embracing the power of asking for help and letting the team conquer some of the obstacles. Asking for help and sharing the vision/village have been key to starting to scale. Am I ready to declare victory? Not even close, but I am learning.

“Who needs actions when you’ve got words” has a bad rap. Words are powerful things. They can be a catalyst for action, or inaction. They can change someone’s outlook on their job (and maybe their life) or solidify someone’s choice in not helping you. The actions behind the words are still very important, but without the right words the actions don’t get us very far on their own. All three of my points could be summarized into one: Communication. The problem with simplifying at that level is that plenty of people communicate, but that alone isn’t enough. I have a million unread emails in my inbox to prove it. The how is very important: attitude makes a huge difference. Be excellent to each other (and no that doesn’t mean you have to be a pushover) -just try it and see what happens.
A special thanks to Ana Vasquez, Mary Stanton, Lauren Malhoit, The In Tech We Trust Podcast Crew and those in my village that always seem to answer the call to help.
Scaling up and Out – Scott and Melissa’s Excellent Adventure
About 6 weeks ago, we were running through internal deep dives of the VMAX All Flash in preparation for launch. I thought, wouldn’t it be cool if we took this great content and explained it simply so that people would understand the architecture and packaging? Here is the resulting video:
https://youtu.be/mPnPo6G4btI
What I love about VMAX All Flash is that it brings our customers performance at scale without sacrificing data services. What other product out there can bring our customers the reliability AND the massive scale they need at a consistent level of performance? Add in the ability to do metro distance active-active clustering in 4 clicks… The future is here kids -and it is beautiful!
I shared the original concept for this idea with my partner in crime, Scott Delandy, who wrote the script for this with me over Twitter DM and went above and beyond to ensure it was successful. Thank you to Scott for jumping in with me on this and activating the team of people that made this video possible. You are awesome! Thanks also to the EMC social media team, Jennifer Rivet, Jessica Kline, Francesca Melchiorri, Adam Temple and Joe Fleischmann for your help in making this video possible.
Enjoy the video. I am excited do more of these videos with Scott. I hope he’s in! As always, feedback is welcome.
Scale, Clouds and Where Things Go Terribly Wrong – a View from the Silicon Forest
Scale is a very important topic. I speak to our customers a lot about scale and the problems that come from doing epic things. I specialize in primary storage and replication, but the solutions I touch involve business-critical and cloud native applications that touch every part of the data center, wherever it lives. I have seen customers build wildly successful clouds from the ground up. I have seen others fail at scaling a single application or process. This is a summation of a few lessons learned over time from watching those successes and failures. It is how I advise my customers on solutions. Their behaviors in these categories drive the solutions I position with them.
The TL:DR:
1. Start with standardization and stick with it
2. Anything worth doing once is worth teaching someone/something else to do it.
3. The answer to the “what problems do you anticipate with this solution?” question is always scale.
Start with standardization and stick with it.
I’ve been on the ground in the Silicon Forest for a while now. I’ve lived and worked here for over a decade. I’ve supported just about every major company in the region in some capacity. There’s incredible value in meeting with all of these IT shops and seeing what they do and how. If you pay attention, there’s a lot to be learned in how people do things and how they don’t. Two of the most successful IT shops I have worked with had the same thing in common: standards for their hardware and software. Every major escalation I’ve worked has a commonality too: snowflakes. Holding on to that one special app from 1983 that runs on an OS that hasn’t been supported for a decade? I don’t care what it does for you, kill it. Kill it with fire. Kill it before it kills your business and my holiday weekend. PLEASE!

Ok, that was an extreme example. I’ve seen many minor settings, small software version discrepancies and other minor “special” tweaks on hosts cause huge performance issues, production outages that cost millions, data corruption and lost jobs. So what does good look like? In short, it looks just like converged infrastructure. If that isn’t an investment you want to make, you build it by choosing one or two hardware skews for server builds, extending the same model to Operating Systems and other data center components. Once you have that established, work with vendors at each layer to come up with a testing plan for all software and firmware upgrades. Put that stuff in a lab. Test. Verify. Go. The fewer variables you have in your data center, the easier it will be to get to that low time to resolution when an issue pops up. The goal is to provide consistent, reliable infrastructure and cut it like cookies. You are not a beautiful or unique snowflake. Being rigorous in enforcing standards will buy time for your IT shop to be flexible in driving the results your business needs. This is how two successful cloud companies started their journey, but even if you aren’t building a giant cloud, there is tremendous value in standardization. If you make exceptions, you are wasting time, money, energy and morale.
Anything worth doing once is worth the time spent teaching someone/something else to do it
This is a life philosophy for me. Any technical task done in the data center eventually gets repeated. (Except maybe accidentally hitting the power switch on your UPS when booting your laptop, but that’s a story for another time.)

I don’t like repetitive tasks. I like to do cool new things, learn and have fun. I’ve had coworkers and seen admins that like to keep their work a secret and do it manually thinking that they are somehow protecting their jobs. We are knowledge workers. We should be spending our time advancing our knowledge to ensure our value. Time spent on repetitive tasks or alone in our work is time we are squandering our value to our employers and our community. The worst I have seen in this scenario is a company who had to rebuild thousands of virtual machines without a single template/image/script. This hurts the standards plan too because no human can repeat a process like that flawlessly that many times. Steps get missed. Here’s what an A+ looks like: bundled automated OS load, scripted software installs based on server role, configuration of cluster via a one-to-many terminal setup, configuration management with naming conventions and processes so well documented (and easily accessible) that any member of the team could pick it up and run with it. Do you need all of this to be successful? No, but it sure doesn’t hurt. For my work, I document everything I do as I do it. This is critical to what I do because I support so many customers and have 9 years of solutions out there -remembering what I did yesterday can be a challenge. I also try to start with scripting my process. I take each command I run and put it in a simple batch script and/or a macro in a spreadsheet. The first pass is manual. Get the process, document and build a repeatable script. On the second pass, I use the base script with some waits and add some intelligence. If someone is shadowing me, I make them run the keyboard and tell them what to do/explain while I document. There are usually a ton of screenshots and hacks listed. I haven’t posted many of these because they were customer-specific, but I plan to convert them into something more generic and put them on github. I’ve never been the person to enjoy giving up my personal time. I’ve never been all that interested in doing the same thing all of my life. I try to share what I know, sometimes it has to be pulled out of me, but that has more to do with all of the things happening in my head than a willingness to share. I feel that the more people know how to do what I do, the more free I am to do whatever excites me next. Automation and knowledge sharing are key to my ability to move and learn more. these are all things you need if you move to the cloud as well. After all:

The answer to the “what problems do you anticipate with this solution?” question is always scale.
II try not to use words like always, but scale is such a big and nebulous thing it’s an easy answer to this question. I try to anticipate and plan for any bottlenecks up front, but the obvious issues are rarely the ones that pop up if you are any good at building a solution. Lab testing just doesn’t happen in life size, and even if it did there are many ways that scale can break a solution. I’ve seen several OpenStack efforts fail due to a lack of resources. As technologists we often underestimate the amount of time we need to spend on care and feeding for a given endeavor. Human scale is vitally important -all the more reason to standardize and automate to eliminate unnecessary work. For a given piece of hardware, there are limits to how high it can scale and limitations on making that choice. Sure, you can build a giant server to handle an app, but eventually that app can surpass the resources of a single server. Scaling up is great until you hit the ceiling and are stuck with an app that chokes on the bottleneck. So then what do we do? We scale out and throw more servers at the problem. Scaling out works for a while, but we almost always outgrow that too. Before the app outgrows the technology, we often find other issues with scale: Fix the component that was once the issue, find a new one. I asked a guy in our IT department about lessons learned from our HANA deployment a few years ago. He said that deploying an in-memory database was a great way to fully expose bad database queries. After years of storage performance reviews and escalations, his answer felt like justice. I wanted to record it and broadcast it outside the offices of all of my customers like John Cusack:

Storage admins, I’m still with you! Scale is the reason we have jobs. It’s what makes my job fun and frustrating. It enables me to revisit solutions every few years and solve the old problem in a brand new way. Every customer and project eventually has issues here. Those that handle the issues the best understand their workloads, standardize, automate and find ways to leverage technology such as non-disruptive migrations in order to account for growth and sudden changes in workload requirements. This is where we learn the most. This is why it is important to standardize and automate as much as possible from the beginning.
In closing, if you want to enjoy your life: standardize, share knowledge and automate. The use of converged infrastructure, public or private clouds can be an “easy button” for getting these things done, but it is possible to build a great environment without it. The issues always arise when operating at scale. Understanding your workload and leveraging advanced data services can help combat issues that arise at scale quickly -provided the proper groundwork has been done.