
This was supposed to be my first post back from my hiatus, but I had two on scale that came first. Here is the post as it was written. It seems fitting to post this today. It’s been a while since I’ve posted anything. I’ve been writing a lot, but the tone of many of the posts just wasn’t where I wanted it. My professional life has changed quite dramatically from the last post. I am now a member of the Leadership team! I help drive the Primary Storage number for the Americas. I’ve learned a lot over the past few months. I’m going to try to stick to the top three.
The TL:DR:
1. Always take the help with the bucket (and help others with theirs too!)
2. The mess you expect is rarely the one you get. Keep your mop handy.
3. The vision you paint needs quite a bit of maintenance. What started as a drawing of a single could very well evolve into an illustrated book about birds.
Always take the help with the bucket (and help others too!)
I spent quite a bit of time in November writing up a business plan and talking to the bulk of my stakeholders about it. I took their input, made a few modifications and had a rock solid plan entering January by the time I found out that I had the job. A week later, massive amounts of change came rolling in. The plan was solid enough to roll through the changes, but it was clear that it needed some adjustments to account for the new teams that needed our help, new products and other roll outs. I had a bucket full of things to do and more and more things kept flying in and forcing other items out of the bucket.

I started talking to people about my plans. Those who were in offered to help. Scott Delandy jumped down the rabbit hole with me on this idea and put in a lot of effort to make it successful. He and I made a video explaining the appliance modeling for the VMAX All Flash with beer! (See previous post.) Lauren Malhoit got me out there on the In Tech We Trust podcast to talk about my role, changes taking place in the industry and other things. The next step there will be an interesting one! I’ve been on the road every week since taking the job except for one, When on that kind of travel sprint, it’s really hard to get all of the extra administrative stuff done, coordinate schedules and keep up with everything that is going on. By hard, I mean impossible to do alone. I’m fortunate to have a team that can divide and conquer, but also to have people in the field that have enough faith in me already to call when they see something that needs attention. I recently caught a dinner with a few other EMC Leaders in Boston. I sat with a few of them and two pulled me aside to give me some encouragement. That whole conversation brightened my spirits for days afterwards. Sometimes all it takes is finding a way to show that someone notices what they are doing and that it matters to make their outlook much brighter. That started a chain of me going out and finding people who were in the same boat: helping, under time pressure and working as hard as they can. Then all it really takes is showing them that I notice. It’s made a huge difference in morale and outlook for the team. I highly recommend taking a step back from a stressful situation and finding those key people that have been putting in the extra work and showing them some appreciation. So many people grind these things out in an atmosphere that feels thankless; a change in tone or a thank you can take you a long way. I am working to get my team to do the same.
The mess you expect is rarely the one you get. Keep your mop handy.
A week into the job the biggest problem I thought I would have in moving the needle and driving results with my team was solved for me. I picked up a new problem: How to help an entirely new set of people, most of which were new to the platforms we support. This is not a bad problem to have to solve at all. More help is always welcome! That said, any time such a shift in priorities happens, a lot of questions come out of the change. Most of my time has been spent talking to people about the importance of this change and how it will be better for us and for our customers. One off my favorite mentors once pulled out a hierarchy of human needs and shared it with me.
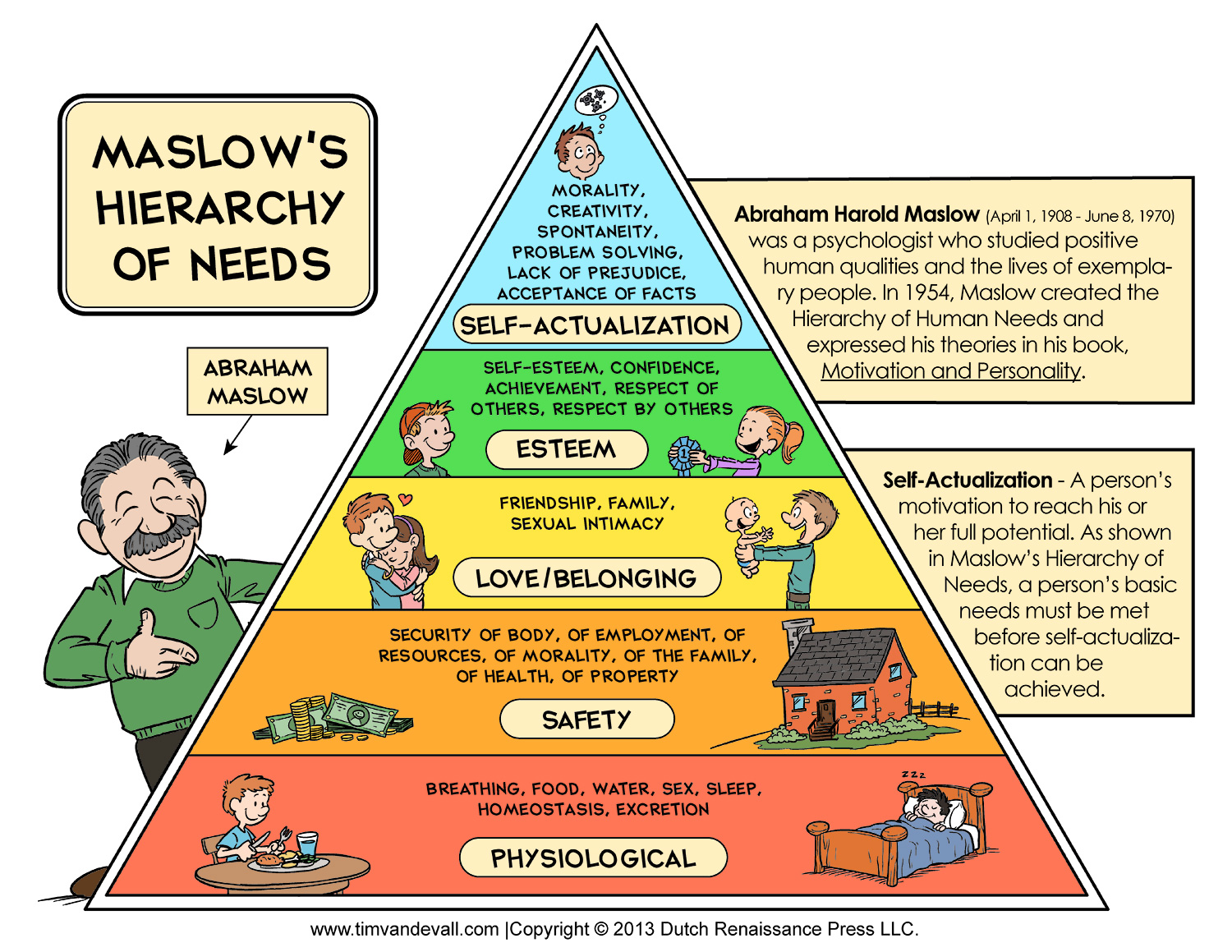
A lot can be learned about how to help someone based on what stage they are at in the hierarchy. This is where the mop comes in. A lot of my work these last two months has been in apologies, genuine assurances and thank yous. It’s about learning how people want to be treated and interacted with: where they find value in their role, what they want to do next and how they prefer to interface with others. This is one of the most messy but also the most rewarding parts of what I do. I come in every day trying to puzzle out how to bring the individuals and the teams closer together… connecting people, discovering what works and what doesn’t.
The vision you paint needs quite a bit of maintenance. What started as a drawing of a bird could very well evolve into an illustrated book about birds
Maybe a Bob Ross reference would have been better, there is always room for more happy trees, but that would have totally killed the Meat Puppets/Nirvana reference. Ideas evolve and change. The simplest concept can grow into a big production, or die on the vine. With the amount of work to do, the best way to do it is to talk to people. Find those people with similar interests and make a suggestion. Once that happens, see where it leads -everyone will have their own spin. The ideas will change and that’s ok. I would love to be the person who just goes out and executes on these things, I had fun doing that stuff. The problem is scale. I can’t drive what’s needed if I do it all. That means some ideas will fail, but it also means that others will succeed in ways I haven’t considered. For the failures, there’s always a chance to try again. I’ve spent a fair bit of time in the past month worrying about getting it all done. More and more, I’m embracing the power of asking for help and letting the team conquer some of the obstacles. Asking for help and sharing the vision/village have been key to starting to scale. Am I ready to declare victory? Not even close, but I am learning.

“Who needs actions when you’ve got words” has a bad rap. Words are powerful things. They can be a catalyst for action, or inaction. They can change someone’s outlook on their job (and maybe their life) or solidify someone’s choice in not helping you. The actions behind the words are still very important, but without the right words the actions don’t get us very far on their own. All three of my points could be summarized into one: Communication. The problem with simplifying at that level is that plenty of people communicate, but that alone isn’t enough. I have a million unread emails in my inbox to prove it. The how is very important: attitude makes a huge difference. Be excellent to each other (and no that doesn’t mean you have to be a pushover) -just try it and see what happens.
A special thanks to Ana Vasquez, Mary Stanton, Lauren Malhoit, The In Tech We Trust Podcast Crew and those in my village that always seem to answer the call to help.



